自动化测试 selenium基础 Selenium核心是基于JS Code来实现的。
现阶段测试中都是使用Selenium+WebDriver来实现自动化测试。
环境搭建:
1.安装Selenium:
1)通过pip install selenium进行安装
2)在Pycharm中的interpreter来进行安装
2.WebDriver安装
在百度搜索WebDriver根据对应版本(Chrome浏览器版本)进行安装即可。
将其放到python根目录下即可。
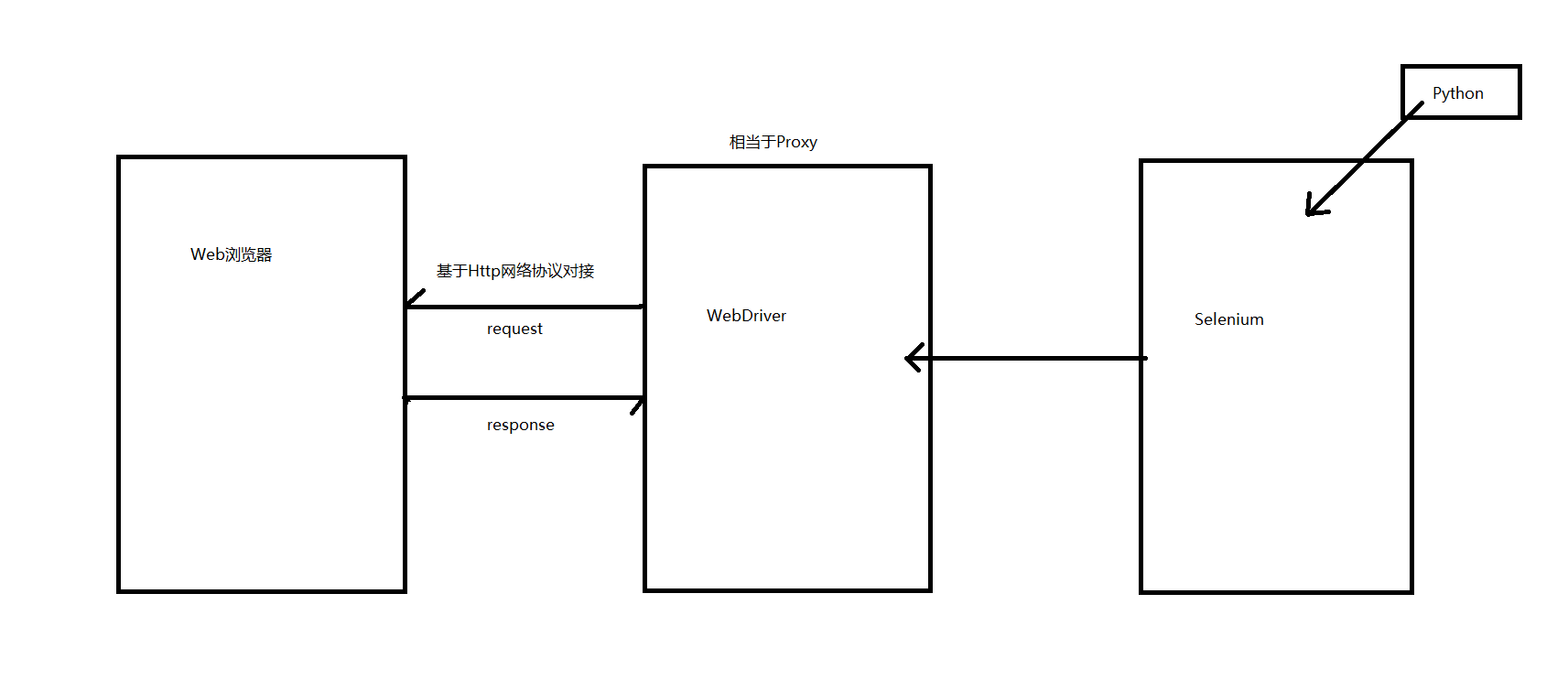
3.WebDriver+Selenium运行原理:
WebDriver其实是一个服务端。
当我们点击chromedriver.exe之后,看到启动了一个服务,由该服务上传下发基于HTTP协议下的指令。
基于封装好的代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from selenium.webdriver.chrome.webdriver import WebDriverfrom selenium.webdriver.common.by import Byfrom time import sleepwb = WebDriver(executable_path="chromedriver" ) wb.execute('get' , {'url' : 'http://www.baidu.com' }) el = wb.execute('findElement' , { 'using' : By.XPATH, 'value' : '//input[@id="kw"]' })['value' ] el._execute('sendKeysToElement' , { 'text' : 'hello world' , 'value' : '' }) el1 = wb.execute('findElement' , { 'using' : By.XPATH, 'value' : '//input[@id="su"]' })['value' ] el1._execute("clickElement" ) sleep(5 ) wb.quit()
基于一般代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from selenium import webdriverfrom time import sleepdriver = webdriver.Chrome() driver.get('http://www.baidu.com' ) myInput = driver.find_element_by_id('kw' ).send_keys('hello world' ) driver.find_element_by_id('su' ).click() sleep(5 ) driver.quit()
八大元素定位法则 所有的ui层次自动化都是基于元素定位来实现的。
所有被操作的元素,都是WebElement对象。
元素==THML标签
实际的系统中,元素的标签类型不是由表象来决定的,使用过CSS来决定的。
八种元素定位 :
id,基于元素属性中id的值来进行定位
name
link text
partial link text
classname
tagname
cssselector
xpath
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from selenium import webdriverfrom time import sleepdriver = webdriver.Chrome() driver.get("http://www.baidu.com" ) sleep(5 ) driver.quit()
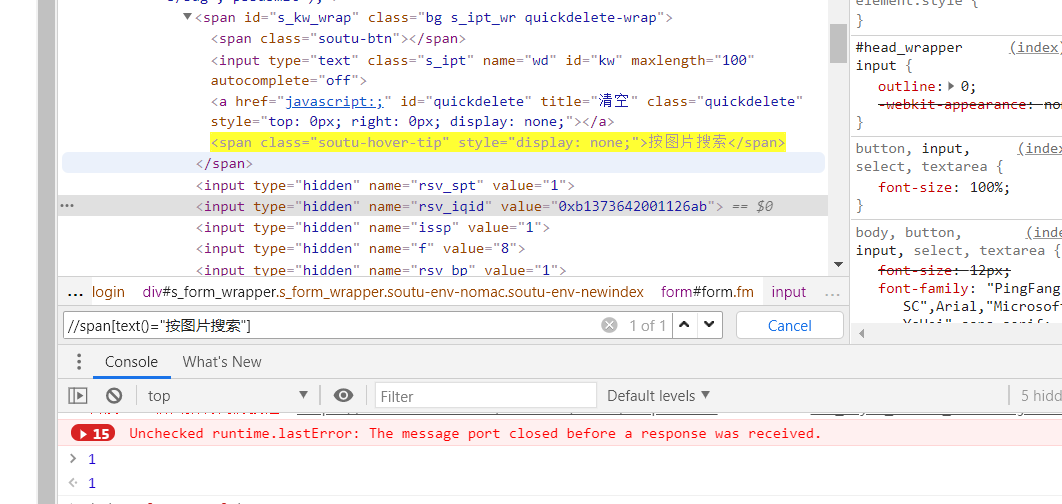
两种确认xpath的方式 :
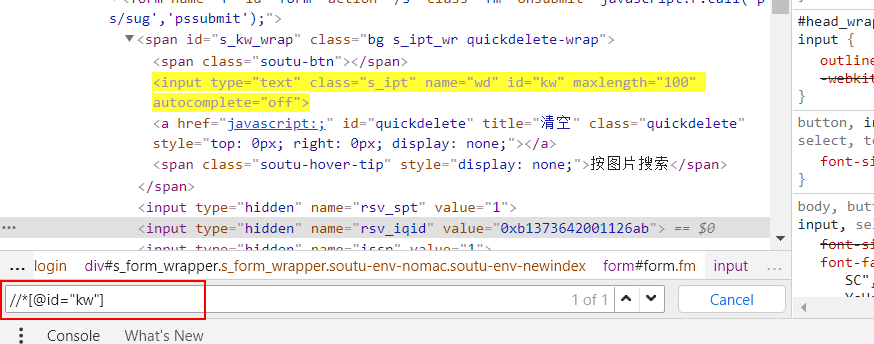
开发者工具中ctrl+F可以搜索xpath
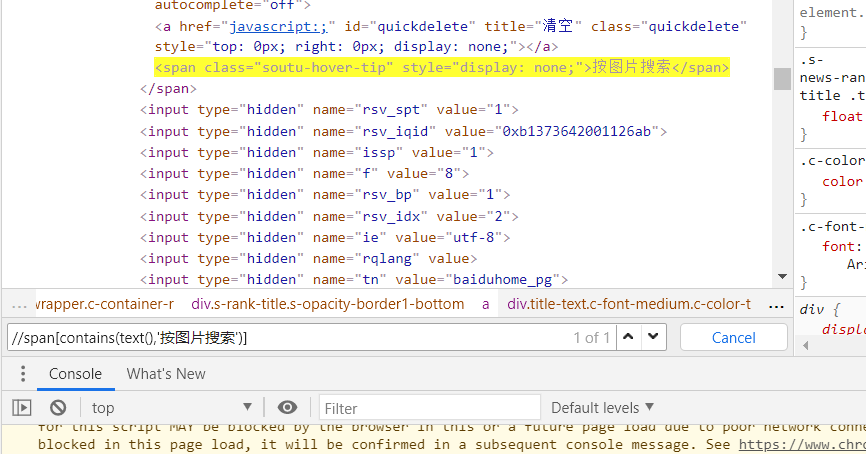
如果要基于text来定位元素(按文本查找)
在[]中添加text()="文本内容"进行查找
查找value(按属性查找)加@即可
通过contains()函数查找
元素操作
clear():清楚文本。send_keys(value):模拟按键输入。click():单击元素。例如按钮操作。Current_url:返回当前页面的url地址。title:返回当前页面的title。Text:获取页面(提示框、警告框)显示的文本。get_attribute(name):获取属性值,文本框中的值使用value属性名。is_displayed():设置该元素是否用户可见,返回true和false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from selenium import webdriverfrom time import sleepclass Testing1 : def __init__ (self) : self.driver = webdriver.Chrome() self.driver.get("https://www.baidu.com" ) def operate (self) : url1 = self.driver.current_url print("url1=>" + url1) self.driver.find_element_by_link_text("新闻" ).click() handles = self.driver.window_handles self.driver.switch_to.window(handles[1 ]) sleep(2 ) url2 = self.driver.current_url print("url2=>" + url2) if url2 is not None : if url2 == "http://news.baidu.com/" : print("跳转页面正确" ) else : print("页面跳转失败" ) else : print("跳转页面失败" ) title = self.driver.title print(title) sleep(5 ) def quit (self) : self.driver.quit() if __name__ == "__main__" : testObj1 = Testing1() testObj1.operate() testObj1.quit()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from selenium import webdriverfrom time import sleepclass Testing2 : def __init__ (self) : self.driver = webdriver.Chrome() self.driver.get("https://www.baidu.com" ) def operate (self) : self.driver.find_element_by_id('kw' ).send_keys('hello world' ) value1 = self.driver.find_element_by_xpath('//*[@id="kw"]' ).get_attribute("value" ) print(value1) value2 = self.driver.find_element_by_xpath('//*[@id="kw"]' ).get_attribute("name" ) print(value2) sleep(3 ) self.driver.find_element_by_id("kw" ).clear() value3 = self.driver.find_element_by_id("su" ).get_attribute("class" ) print(value3) if self.driver.find_element_by_id("su" ).is_displayed(): print("搜索按钮正常显示了" ) else : print("显示失败" ) if self.driver.find_element_by_id("su" ).is_enabled(): print("搜索按钮可用" ) else : print("搜索按钮不可用" ) sleep(3 ) def quit (self) : self.driver.quit() if __name__ == "__main__" : testObj2 = Testing2() testObj2.operate() testObj2.quit()
浏览器操作 webDriver主要提的是操作页面上各种元素的方法,但它也提供了浏览器的一些操作方法。
控制浏览器窗口大小
让浏览器以某种尺寸打开,让访问的网页在这种尺寸下运行。webriver提供了Set_window_size()方法来设置浏览器大小。
maximize_window()方法最大化窗口。
控制浏览器后退、前进
在使用浏览器浏览网页时,浏览器提供了前进后退按钮,可以方便的在浏览过的页面之间来回切换,weDriver也提供了对应的back()和forward()方法来进行模拟后退和前进按钮。
模拟浏览器刷新
refresh()方法
截屏操作
将运行的页面截图保存在本地,推荐使用png格式:driver.save_screenshot(r"e:\abc.png)
模拟浏览器关闭
webDriver提供两种关闭方法,close()关闭单个页面,quit()关闭所有页面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from selenium import webdriverimport timeclass Testing3 : def __init__ (self) : self.driver = webdriver.Chrome() self.driver.get("https://www.baidu.com/" ) def setWindow (self) : self.driver.maximize_window() def backForward (self) : self.driver.find_element_by_link_text("新闻" ).click() self.driver.back() time.sleep(2 ) self.driver.forward() def refresh (self) : self.driver.refresh() def screenShot (self) : self.driver.get_screenshot_as_file("{}.{}" .format("e:/aaa" , "png" )) def quit (self) : time.sleep(3 ) self.driver.quit() def closeWindow (self) : self.driver.close() if __name__ == "__main__" : testObj3 = Testing3() testObj3.setWindow() testObj3.backForward() testObj3.screenShot() testObj3.closeWindow() testObj3.quit()
多窗口和鼠标操作 多窗口操作 句柄(handler):每一个页面都有一个值,对一个页面来说是唯一的,是页面的一个标识。
获取所有的句柄:driver.window_handles
获取的是一个数组。
根据数组切换到对应的句柄:driver.switch_to.window[drivers[数组下标]]
鼠标操作 鼠标事件,前面讲到的click()是模拟鼠标的单击操作,现在的web产品提供了更丰富的交互方式,如鼠标右击、双击、悬停、甚至是鼠标拖动的功能。WebDriver中,这些方法封装在ActionChains类中,需要导入以下包:from selenium.webdriver.common.action_chains import ActionChains
常见方法:
perform():执行所有ActionChains中存储的行为
context_click():右击double_click():双击drag_and_drop():拖动move_to_element():鼠标悬停
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from selenium import webdriverimport timefrom selenium.webdriver.common.action_chains import ActionChainsclass Testing5 : def __init__ (self) : self.driver = webdriver.Chrome() def get (self, url) : self.driver.get(url) time.sleep(2 ) def mouseOverOperate (self) : self.driver.maximize_window() setButton = self.driver.find_element_by_id('s-usersetting-top' ) ActionChains(self.driver).move_to_element(setButton).perform() def rightClick (self) : webEdit = self.driver.find_element_by_id("kw" ) ActionChains(self.driver).context_click(webEdit).perform() def quit (self) : time.sleep(5 ) self.driver.quit() if __name__ == "__main__" : testObj5 = Testing5() testObj5.get("https://www.baidu.com/" ) testObj5.rightClick() testObj5.quit()
键盘操作 键盘事件,Keys()类提供了键盘上几乎所有的按键方法。前面了解到,send_keys()方法可以用来模拟键盘输入,除此之外,我们还可以用它来输入键盘上的按键,甚至是组合键,如Ctrl+A,Ctrl+C等,需要导入以下包:from selenium.webdriver.common.keys import keys
Send_keys(Keys.Back_SPACE):删除键
Send_keys(Keys.SPACE):空格键
Send_keys(Keys.TAB):制表键
Send_keys(Keys.ESCAPE):esc键
Send_Keys(Keys.ENTER):回车键
Send_keys(Keys.CONTROL,'a'):全选
Send_keys(Keys.CONTROL,'c'):复制
Send_keys(Keys.CONTROL,'x'):剪切
Send_keys(Keys.CONTROL,'y'):粘贴
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport timeclass Testing6 : def __init__ (self) : self.driver = webdriver.Chrome() def get (self, url) : self.driver.get(url) def keysOperate (self) : self.driver.find_element_by_id("kw" ).send_keys("seleniumm" ) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(Keys.BACK_SPACE) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(" 教程" ) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(Keys.CONTROL, 'a' ) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(Keys.CONTROL, 'x' ) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(Keys.CONTROL, 'v' ) time.sleep(1 ) self.driver.find_element_by_id("kw" ).send_keys(Keys.ENTER) def quit (self) : time.sleep(5 ) self.driver.quit() if __name__ == "__main__" : test6Obj = Testing6() test6Obj.get("https://www.baidu.com/" ) test6Obj.keysOperate() test6Obj.quit()
警告窗口处理
在WebDriver中处理JavaScript所生成的
使用方式:switch_to_alert()
方法定位到alert/confirm/prompt,然后使用:
text:返回(获取)alert/confirm/prompt中的文本信息。accept():接受现有警告框。dismiss():放弃现有警告框。send_keys(KeysToSend):发送文本至警告框。
如何操作警告框alert:
driver对象是在当前页窗口内,但是不在altert上,并且我们没办法去定位这个窗口的元素。driver.switch_to.alert:暂时将浏览器对象driver交给alert对alert警告框进行操作:
text:返回(获取)alert/confirm/prompt中的文本信息。accept():接受现有警告框,点击确定按钮。dismiss():放弃现有警告框。send_keys(KeysToSend):发送文本至警告框。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from selenium import webdriverimport timefrom selenium.webdriver import ActionChainsclass Testing7 : def __init__ (self) : self.driver = webdriver.Chrome() def get (self, url) : self.driver.get(url) def mouseOverOperate (self) : self.driver.maximize_window() setButton = self.driver.find_element_by_id('s-usersetting-top' ) ActionChains(self.driver).move_to_element(setButton).perform() time.sleep(1 ) def alertOperate (self) : self.driver.find_element_by_link_text("搜索设置" ).click() time.sleep(2 ) self.driver.find_element_by_id('SL_1' ).click() time.sleep(2 ) self.driver.find_element_by_xpath('//*[@id="wrapper"]/div[6]/div/div/ul/li[2]' ).click() time.sleep(2 ) self.driver.find_element_by_xpath('//span[@class="c-select-selected-value"]' ).click() time.sleep(2 ) self.driver.find_element_by_xpath('//*[@id="adv-setting-gpc"]/div/div[2]/div[2]/p[4]' ).click() time.sleep(2 ) self.driver.find_element_by_xpath('//li[@data-tabid="general"]' ).click() time.sleep(2 ) self.driver.find_element_by_link_text("保存设置" ).click() time.sleep(2 ) alertDriver = self.driver.switch_to.alert text = alertDriver.text print(text) time.sleep(2 ) alertDriver.accept() def quit (self) : time.sleep(5 ) self.driver.quit() if __name__ == "__main__" : testObj7 = Testing7() testObj7.get("https://www.baidu.com/" ) testObj7.mouseOverOperate() testObj7.alertOperate() testObj7.quit()
多表单操作 在Web应用中经常会遇到frame/iframe表单嵌套页面的应用,WebDriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌页面上的元素无法直接定位。
这时就需要通过switch_to.frame()方法将当前定位的主体切换为frame/iframe表单的内嵌页面中。
比如腾讯qq邮箱的用户提交模块就是嵌套处理的,如果想要输入用户名、密码等信息就要切换表单才可以。
Webdriver对象只能在一个页面(默认是外层)中定义元素,需要一种方式将driver对象从外层切换给内层使用才能对内层的对象进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from selenium import webdriverimport timeclass Testing8 : def __init__ (self) : self.driver = webdriver.Chrome() def get (self, url) : self.driver.get(url) def multiFrame (self) : self.driver.find_element_by_link_text("Qmail" ).click() handles = self.driver.window_handles self.driver.switch_to.window(handles[1 ]) iframeObj = self.driver.find_element_by_xpath('//*[@id="login_frame"]' ) self.driver.switch_to.frame(iframeObj) self.driver.find_element_by_id('u' ).send_keys("2011268822" ) self.driver.find_element_by_id('p' ).send_keys("2011268822" ) def quit (self) : time.sleep(5 ) self.driver.quit() if __name__ == "__main__" : testObj8 = Testing8() testObj8.get("https://www.qq.com/" ) testObj8.multiFrame() testObj8.quit()
元素等待 如今很多web都在使用ajax技术,运用这种技术的软件当浏览器加载页面时,页面上的元素可能不会被同步加载完成,如此一来,定位元素时就会出现困难。我们可以通过设置元素等待来改善这类问题导致的测试脚本不稳定。
webDriver提供了三种元素等待方式:
强制等待 :time.sleep(5),休眠5秒,就是直接让线程休眠。
隐式等待 :在脚本创建driver对象之后,给driver设置一个全局的等待时间,对driver的整个生命周期(创建到关闭)都起效。如果在设置等待时间(超时时间)内,定位到了页面元素,则不再等待,继续执行下面的代码;如果超出了等待的时间,则抛出异常。
注意:使用隐式等待的时候,实际上浏览器会在你自己设定的时间内不断地刷新页面去寻找我们需要
语法:implicity_wait(),单位秒
显示等待 :显示等待就是明确要找到某个元素 地出现或者某个元素地可点击条件,等不到,就一直等,除非在规定的时间之内都没有找到,那么就抛出Exception。(简而言之,就是等到元素出现才操作,如果超时则报异常)。
需要的包:
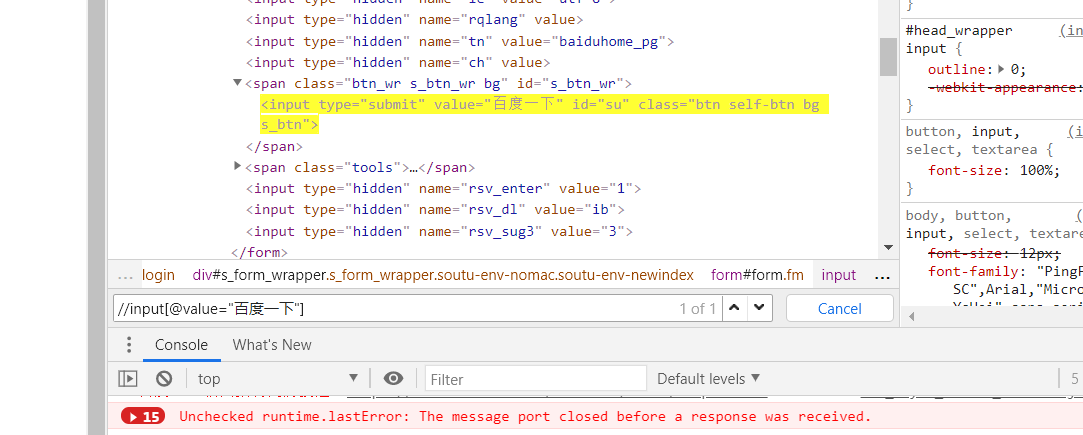
例子:使用显示等待的方式去等百度首页的百度一下按钮显示出来,如果出来就点击,否则打印。
使用到的方法:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
util(method,info):直到满足某一个条件,返回结果,等不到就抛错
expected_conditions.presence_of_element_located(locator):判断某个元素是否定位到了
隐式等待 是对全局的等待。
显示等待 专注于等待某个元素
若同时设置了隐式等待 和显示等待 ,则以隐式等待为第一优先级,也就是说,若隐式等待时间大于显示等待,显示等待时间设置无效,因为driver若找不到元素,会先等待隐式等待的时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from selenium import webdriverimport timefrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECclass Testing9 : def __init__ (self) : self.driver = webdriver.Chrome() def get (self, url) : self.driver.get(url) def operate (self) : ele = WebDriverWait(self.driver, 10 , 0.5 , ignored_exceptions=None ).until( EC.presence_of_element_located((By.ID, "kw" )), "找不到" ) print(ele) if ele: ele.send_keys("selenium" ) else : print("找不到" ) def quit (self) : time.sleep(5 ) self.driver.quit() if __name__ == "__main__" : testObj9 = Testing9() testObj9.get("https://www.baidu.com/" ) testObj9.operate() testObj9.quit()
自动化测试用例
自动化测试用例一般可以由手工测试用例转化而来,需注意
不是所有的手工测试都要转化为自动化测试用例
考虑到脚本开发的成本,不要选择流程太复杂的用例,可以把流程拆分为多个用例
选择的用例最好可以构成场景
选取的用例可以是你认为是重复执行、很耗时间的部分,例如字段验证
选取的用例可以是主流程用例,即适用于冒烟测试的用例
自动化测试用例的设计原则
一个用例为一个完整的场景,从用户登录到最终退出并关闭浏览器。
一个用例只验证一个功能点,不要试图在用户登录后把所有的功能都验证一遍。
尽可能少的编写逆向测试用例,一方面因为逆向逻辑的用例很多,另一方面自动化测试脚本本身比较脆弱。
用例与用例之间尽量避免产生依赖。
一条用例测试完之后需要对测试场景进行还原,以免影响其它用例的执行。
自动化测试用例设计实践
测试点转为测试用例的原则:
设计一条正向用例,覆盖足够多的有效等价类数据。
设计一条反向用例,需要覆盖一条无效等价类数据,其他数据一概使用正向数据。
有验证码的时候:
让开发暂时屏蔽验证码,将验证码改为万能码
通过机器学习训练样本
调用OCR的接口,去解析图片中的验证码
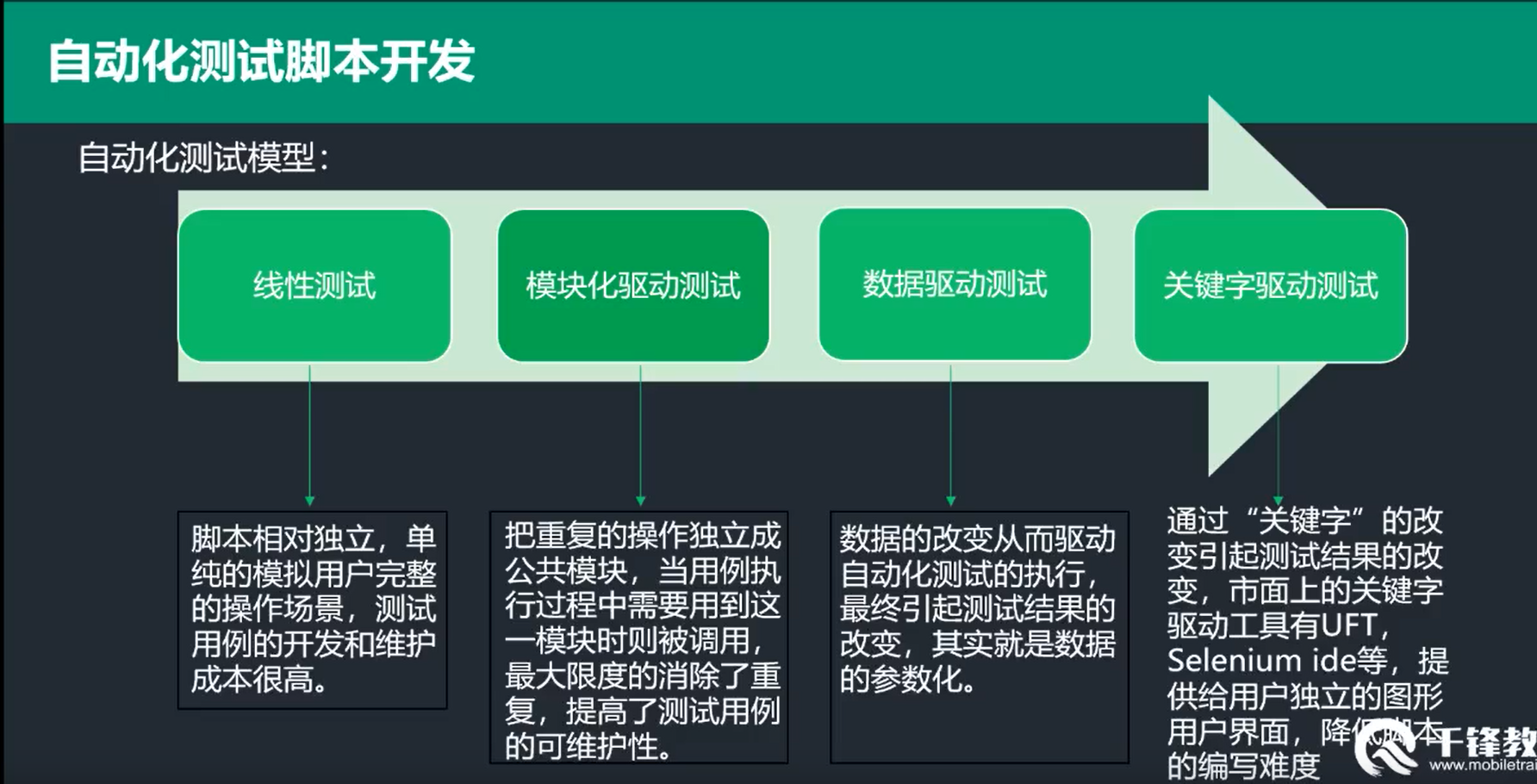
自动化脚本开发
线性测试 最基本的代码组织形式
维护性差
模块比较多,运行起来很麻烦
如果所有用例的步骤都放在一个模块中,可读性非常差
解决方式:写一个额外的模块作为主运行模块,把用到的模块都引入
进去即可。
模块化测试 把重复操的操作独立成公共模块,当用例执行过程中需要用到这一模块时则被调用,最大限度的消除了重复,提高了测试用例的可维护性、复用性。
把常用的、公用的一些功能、业务、步骤专门提取出来,写在一个专门的模块中,以方法,类的形式体现出来,其他模块如果需要这些功能,直接调用即可,无需重复显示这些代码。比如登录模块,退出模块,邮件发送模块,数据库处理模块、日志生成模块等。
数据驱动测试 数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变,其实就是数据的参数化。
数据测试驱动即:数据与业务的分离
例如,现在我要测试不同用户的登录,首先用的是”张三”的用户名登录;下一个测试用例要换成”李四的用户名登录”,这时候就需要对数据进行参数化。
参数化的方式有很多,可以通过定义列表 、字典 的方式,还可以读取文件(txt/csv/xml) 的方式进行参数化。下面主要讲解三种参数化的方式:
采用列表
采用字典
采用csv
字典 :
在python定义一个字典类型的数据结构,把数据存进去。
数据量比较小,只有几个的时候,使用的频率还挺高的时候,可以使用字典。
csv文件(excel) :
数据量比较大的时候,几十到几万条数据比如,使用的频率不算太高,可现在csv和excel文件中。
数据库 :
数据非常大,通常是几万起步的数据量,直接存储在数据库,通过数据库获取想要的数据即可。
最字典数据的读写 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from selenium import webdriverimport timefrom data_driven_testing import NormalOperationclass dicData : dictData = [{"username" : "" , "password" : "123456" }, {"username" : "2011268823s" , "password" : "123456" }, {"username" : "_201126" , "password" : "123456" }, {"username" : "20dw@sjfief" , "password" : "123456" }] normalObj = NormalOperation.NormalOperation() def operate (self) : for d in self.dictData: print(d) self.normalObj.get("https://mail.qq.com/" ) self.normalObj.driver.switch_to.frame("login_frame" ) self.normalObj.driver.find_element_by_id('u' ).send_keys(d['username' ]) self.normalObj.driver.find_element_by_id('p' ).send_keys(d['password' ]) self.normalObj.driver.find_element_by_id('login_button' ).click() expectUrl = "https://mail.qq.com/" currentUrl = self.normalObj.driver.current_url if currentUrl == expectUrl: print("注册username反向测试用例成功" ) else : print("注册username反向测试用例失败" ) self.normalObj.quit() if __name__ == "__main__" : dictDataObj = dicData() dictDataObj.operate() """ {'username': '', 'password': '123456'} 注册username反向测试用例成功 {'username': '2011268823s', 'password': '123456'} 注册username反向测试用例成功 {'username': '_201126', 'password': '123456'} 注册username反向测试用例成功 {'username': '20dw@sjfief', 'password': '123456'} 注册username反向测试用例成功 """
csv文件的创建
创建一个excel文件,录入数据。
将excel文件另存为utf-8格式的带逗号分隔符的csv文件。
将csv文件转码为utf-8格式
csv文件的读取 1 2 with open(r"./data_driven_teseting/data_csv.csv" ,"r" ,encoding="utf-8" ) as f: data = csv.reader(f)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from selenium import webdriverfrom class2 import Testing8import timeimport csvimport osclass Verify_login_username_csv : @staticmethod def test () : with open(os.path.dirname(__file__)+"/data_csv.csv" , "r" , encoding="utf-8" ) as f: data = csv.reader(f) print(data) for d in data: print(d) driver = webdriver.Chrome() driver.get('https://mail.qq.com/' ) driver.switch_to.frame('login_frame' ) driver.find_element_by_id('u' ).send_keys(d[0 ]) driver.find_element_by_id('p' ).send_keys(d[1 ]) driver.find_element_by_id('login_button' ).click() expectUrl = "https://mail.qq.com/" currentUrl = driver.current_url if currentUrl == expectUrl: print("注册username反向测试用例成功" ) else : print("注册username反向测试用例失败" ) time.sleep(3 ) driver.quit() if __name__ == "__main__" : Verify_login_username_csv.test() """ ['', '123456', '请设置用户名'] 反向测试用例成功 ['2011268823', '123456', '用户名不符合格式要求'] 反向测试用例成功 ['_201126', '123456', '用户名不符合格式要求'] 反向测试用例成功 ['20dw@sjfief', '123456', '用户名不符合格式要求'] 反向测试用例成功 """
excle文件的读写 xlrd模块的使用:
安装:pip install xlrd
导包:import xlrd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from data_driven_testing import NormalOperationimport xlrdimport osclass Verify_login_username_excel : normalObj = NormalOperation.NormalOperation() def test (self) : filename = os.path.dirname(__file__) + "/data_excel.xls" data = xlrd.open_workbook(filename) print(data) datatable = data.sheet_by_name("Sheet1" ) print(datatable) nrow = datatable.nrows ncol = datatable.ncols print(nrow) print(ncol) cellValue = datatable.cell(0 , 1 ).value print(cellValue) print(datatable.row_values(0 )) print(datatable.col_values(0 )) for i in range(nrow): self.normalObj.get("https://mail.qq.com/" ) self.normalObj.driver.switch_to.frame('login_frame' ) self.normalObj.driver.find_element_by_id('u' ).send_keys(datatable.row_values(i)[0 ]) self.normalObj.driver.find_element_by_id('p' ).send_keys(int(datatable.row_values(i)[1 ])) self.normalObj.driver.find_element_by_id('login_button' ).click() expectUrl = "https://mail.qq.com/" currentUrl = self.normalObj.driver.current_url if currentUrl == expectUrl: print("注册username反向测试用例成功" ) else : print("注册username反向测试用例失败" ) self.normalObj.quit() if __name__ == "__main__" : verifyLoginObj = Verify_login_username_excel() verifyLoginObj.test()
pyhton获取当前文件的目录:os.path.dirname(__file__)
pyhton获取当前文件的上级目录:os.path.dirname(os.path.dirname(__file__))
关键字驱动测试 Unittest单元测试框架 之前脚本存在问题:
用例过多时,不好导包。
断言方式应该显示在报告中,而不是控制台。
看不到测试的结果。
unittest框架很好的解决了这些问题。
单元测试:包括两部分,代码级别的功能验证 ,逻辑覆盖 。
测试用例介绍:
提供用例组织与执行
当测试用例达到成百上千条的时候,大量的测试用例堆积在一起,就产生了扩展性和维护性的问题,此时需要考虑用例的规范与组织问题。
提供丰富的断言方法
用例执行完之后都需要将实际结果与预期结果进行比较(断言),从而断定用例是否通过。
提供丰富的日志和报告
测试用例执行失败时能抛出清晰的失败原因,当所有用例执行完成后能提供丰富的执行结果。
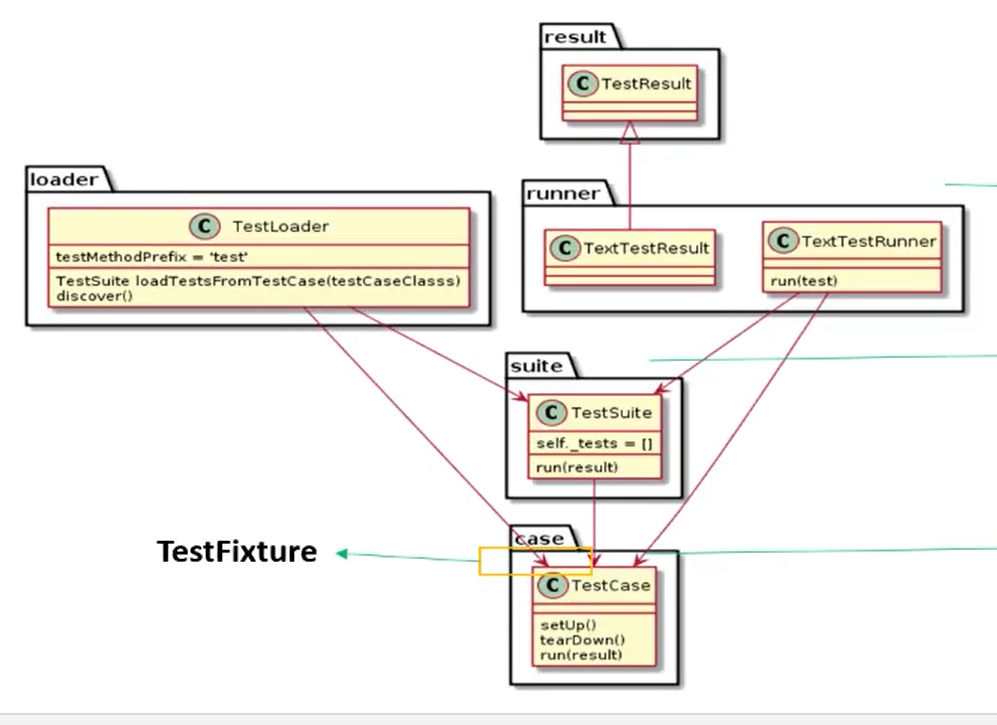
Unittest工作原理 TestCase 一个TestCase的实例就是一个测试用例。测试用例就是一个完整的测试流程,包括测试前准备环境的搭建(setUp),执行测试代码(test),以及测试后环境的还原(tearDown)。
TestSuite 多个测试用例集合在一起,就是TestSuite。
TestLoader是用来加载TestCase到TestSuite中,其中有几个loadTestForm_()方法,就是从各个地方寻找TestCase,创建它们的实例,然后add到TestSuite中,再返回一个TestSuite实例。
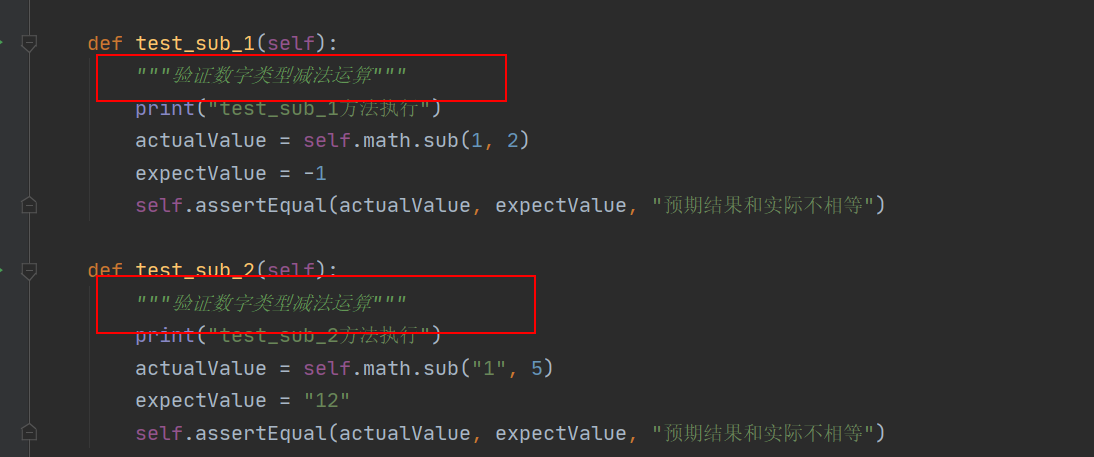
TestCase和TestSuite代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 """ 使用unittest步骤: 1.导包,import unittestProgram 2.创建一个单元测试用例类(继承单元测试框架单元测试用例的类) 3.单元测试类中的五个特殊的方法的使用: setUp(),test_xxx(),tearDown(),不管如何调整,顺序都是这样的,类似于生命周期 setUp():主要进行测试用例的资源初始化,测试用例的前提条件写在这 test_xxx():测试用例,要把测试用例的步骤写在此方法中 tearDown():主要是进行测试用例的资源释放 @classMethod:注解的方法是类方法,不用创建对象也能用,在对象进内存之前就已经存在 setUpClass:给当前单元测试类的所有的用例进行初始化 tearDownClass:给当前单元测试类的所有用例进行资源释放 setUpClass和setUp的区别: setUp()不需要@classMethod注解 setUp()实例方法,就需要创建对象再调用,setUpClass类方法,不需要创建也可以调用 setUp()在每一个测试用例之前运行一次,setUpClass方法在测试执行之前只执行一次 setUp()对一条测试用例初始化,setUpClass()给当前单元测试类的所有用例进行初始化 4.测试用例执行: main():把所有的测试用例执行一遍,我们发现测试用例执行的顺序是控制不了的(默认按照用例名字母顺序排序的) testSuite是测试集合的概念: 1.比如把加法的测试用例加到一个测试集合testSuite中,只运行该测试集合即可 2.调用testSuite中的方法addTest,addTests()将测试用例加入测试集合 3.testSuite的run()方法运行测试集合 TestLoader: 1.创建TestLoader对象:loader = unittest.TestLoader() 2.使用loader的方法loadTestsFromName()将指定的测试用例加载到测试集合,并返回给测试集合 1.参数可以是模块名字:UnitMyMath 2.可以是模块中的类名:UnitMyMath.UnitMyMath 3.可以是模块中类中的某一用例:UnitMyMath.UnitMyMath.test_add_1 3.使用loader的discover方法(掌握),将指定的文件(模块)中的测试用例一次性加载 1.discover = unittest.defaultTestLoader.discover(os.path.dirname(__name__), pattern="Unit*.py") 1.path:指定存放单元测试用例的目录 2.pattern:指定匹配规则:Testing*.py """ import osimport unittestfrom unittestProgram import Testing1class UnitMyMath (unittest.TestCase) : @classmethod def setUpClass (cls) : print("setUpClass方法" ) @classmethod def tearDownClass (cls) : print("tearDownClass方法" ) def setUp (self) : print("setup method" ) self.math = Testing1.Testing1() def test_add_1 (self) : print("第一条测试用例" ) actualValue = self.math.add(10 , 11 ) expectValue = 21 self.assertEqual(actualValue, expectValue, "预期结果和实际不相等" ) def test_add_2 (self) : print("第二条测试用例" ) actualValue = self.math.add("a" , "123" ) expectValue = "a123" self.assertEqual(actualValue, expectValue, "预期结果和实际不相等" ) def test_mul_1 (self) : print("第三条测试用例" ) actualValue = self.math.mul(4 , 5 ) expectValue = 20 self.assertEqual(actualValue, expectValue, "预期结果和实际不相等" ) def tearDown (self) : print("tearDown方法" ) self.math = None if __name__ == "__main__" : suite = unittest.TestSuite() discover = unittest.defaultTestLoader.discover(os.path.dirname(__file__), pattern="MyMath*.py" ) res = unittest.TestResult() discover.run(res) print(discover.countTestCases())
TestRunner 测试的执行也是单元测试中非常重要的一个概念,一般单元测试框架中都会提供丰富的执行策略和执行结果。在unittest单元测试框架中,通过TextTestRunner类提供的run()方法来执行testsuite/testcase。测试的结果会保存到TextTestResult实例中,包括运行了多少测试用例,成功了多少,失败了多少等信息。
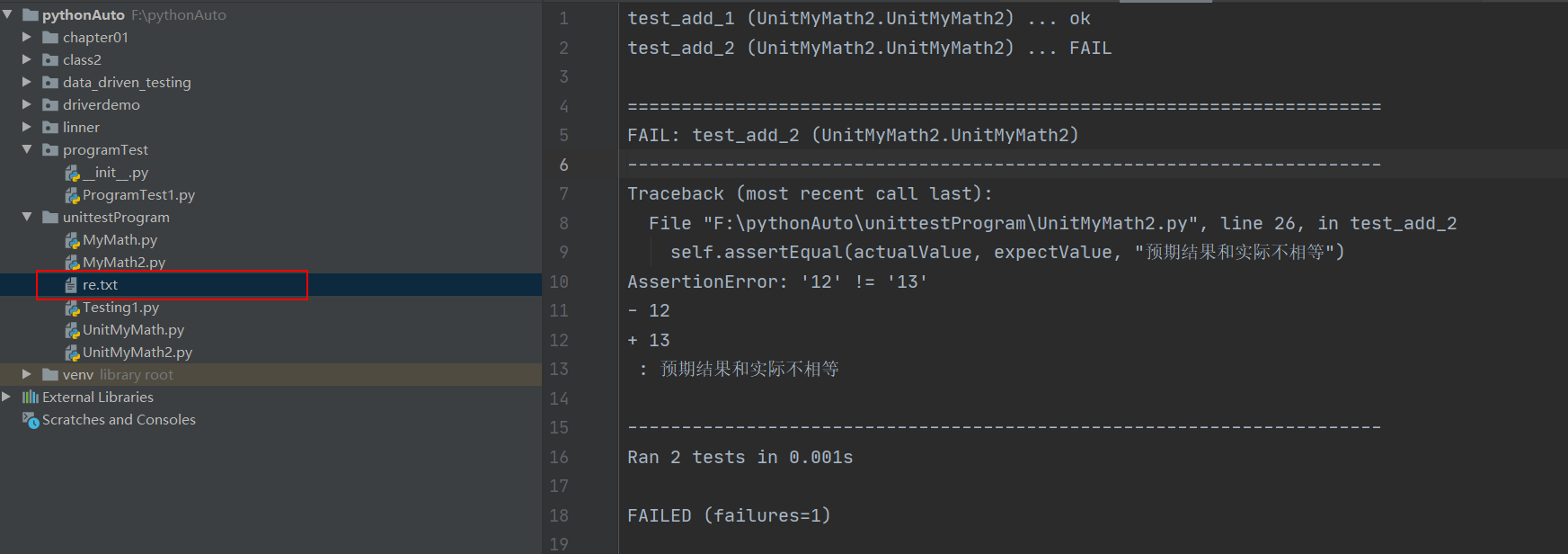
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 """ TestRunner: 在前面测试用例,测试集合执行的时候都是用testSuite()的run()方法:suite.run(result) TextTestRunner()=>将结果能够以text的形式展示的运行器 断言: assertEqual(a,b,msg=""):判断a和b是否相等,如果相等,则断言成功.如果不相等,则断言失败 assertNotEqual(a,b,msg=""):判断a和b是否不相等 assertTrue(a):判断a是否为True这个bool值 assertFalse(a):判断a是否为False这个bool值 assertIs(a,b,msg=""):判断a和b的内存地址是否相等 assertIsNot(a,b,msg=""):判断a和b的内存地址是否不相等 assertIsNone(a):判断对象a是不是空指针,没有指向堆内存空间 assertIsNotNone(a):判断对象a是不是不是空指针,指向堆内存空间 assertIsInstance(a,b):判断a是不是b的成员,是则断言成功 assertNotIsInstance(a,b):判断a不是b的成员,如果确实不是,则断言成功 """ import osimport unittestfrom unittestProgram import Testing1class UnitMyMath2 (unittest.TestCase) : def setUp (self) -> None : print("setUp方法执行" ) self.math = Testing1.Testing1() def test_add_1 (self) : print("test_add_1方法执行" ) actualValue = self.math.add(1 , 2 ) expectValue = 3 self.assertEqual(actualValue, expectValue, "预期结果和实际不相等" ) def test_add_2 (self) : print("test_add_2方法执行" ) actualValue = self.math.add("1" , "2" ) expectValue = "12" self.assertEqual(actualValue, expectValue, "预期结果和实际不相等" ) def test_mul_1 (self) : print("test_mul_1执行" ) actualValue = self.math.mul(10 , 5 ) expectValue = 50 self.assertEqual(actualValue, expectValue, "预期结果和实际不符" ) def test_sub_1 (self) : actualValue = self.math.sub(5 ,1 ) expectValue = 4 self.assertEqual(actualValue,expectValue,"预期和实际结果不一致" ) def test_divide_1 (self) : actualValue = self.math.divide(5 , 1 ) expectValue = 5 self.assertEqual(actualValue, expectValue, "预期和实际结果不一致" ) def tearDown (self) -> None : print("tearDown方法执行" ) self.math = None if __name__ == "__main__" : discover = unittest.defaultTestLoader.discover(os.path.dirname(__file__), pattern="UnitMyMath2.py" ) with open(os.path.dirname(__file__) + "/re.txt" , "w" , encoding="utf-8" ) as f: runner = unittest.TextTestRunner(f, descriptions="用于测试math类的用例执行" , verbosity=2 ) runner.run(discover)
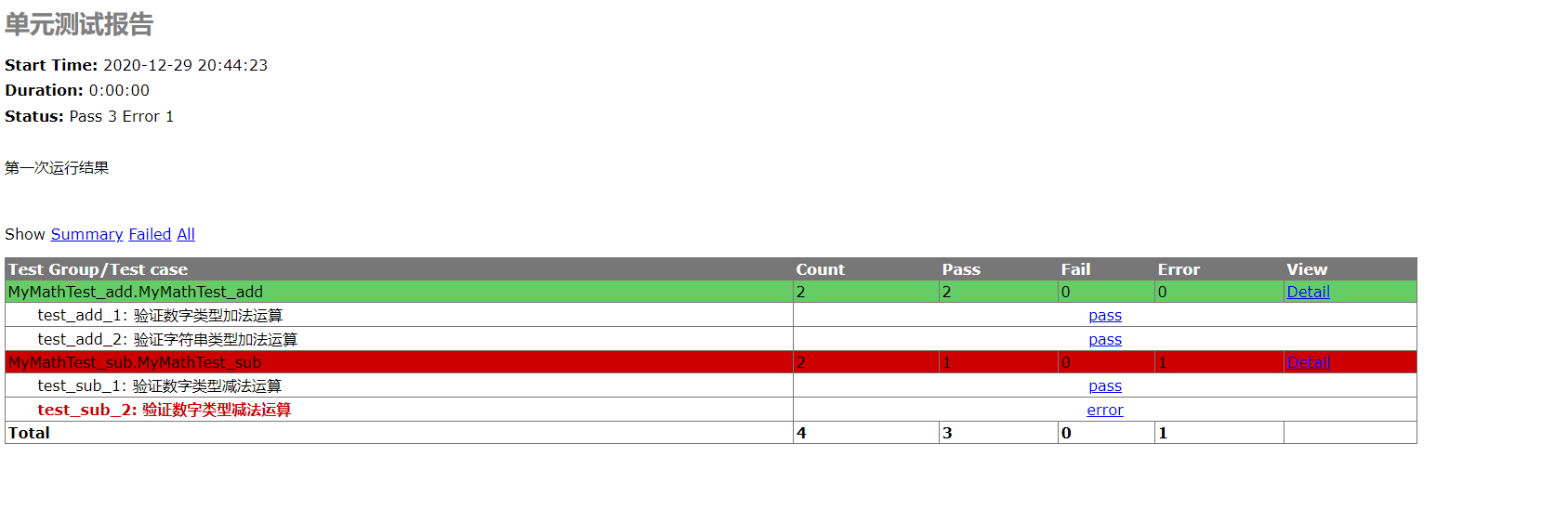
可以发现,其中有一个测试用例断言失败了,也不影响其他的用例执行。
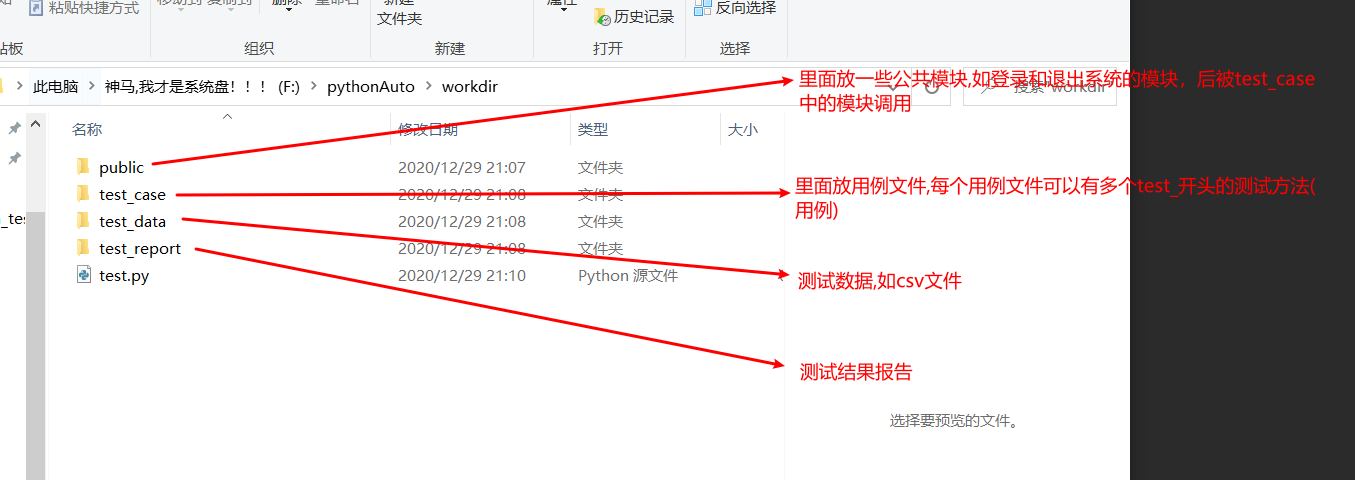
一般我们创建个主测试文件,来统一组织用例执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import osimport unittestfrom unittestProgram import MyMathTest_addclass MainTest : def main (self) : self.discover = unittest.defaultTestLoader.discover(os.path.dirname(__file__), pattern="MyMathTest*.py" ) with open(os.path.dirname(__file__) + "/result.txt" , "w" , encoding="utf-8" ) as f: runner = unittest.TextTestRunner(f, descriptions="测试用例" , verbosity=2 ) runner.run(self.discover) if __name__ == "__main__" : mainObj = MainTest() mainObj.main()
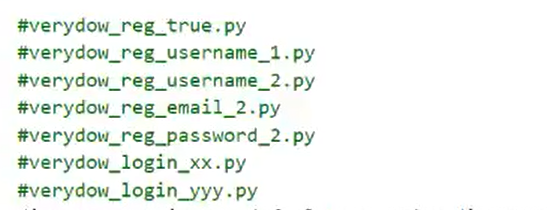
文件命名规范应该如下,这样可方便调用:
HTMLTestRunner模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import osimport unittestfrom unittestProgram import MyMathTest_addfrom HTMLTestRunner import HTMLTestRunnerclass MainTest : def main (self) : self.discover = unittest.defaultTestLoader.discover(os.path.dirname(__file__), pattern="MyMathTest*.py" ) with open(os.path.dirname(__file__) + "/result.html" , "w" , encoding="utf-8" ) as f: runner = HTMLTestRunner.HTMLTestRunner(f, verbosity=2 , title="单元测试报告" , description="第一次运行结果" ) runner.run(self.discover) if __name__ == "__main__" : mainObj = MainTest() mainObj.main()
给用例加上文档字符串
采用时间的方式命名文件名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import osimport timeimport unittestfrom unittestProgram import MyMathTest_addfrom HTMLTestRunner import HTMLTestRunnerclass MainTest : def main (self) : self.discover = unittest.defaultTestLoader.discover(os.path.dirname(__file__), pattern="MyMathTest*.py" ) filename = time.strftime("%Y-%m-%d-%H-%M-%S" ) path = os.path.dirname(__file__) print(filename) with open(path + "/" +filename+".html" , "w" , encoding="utf-8" ) as f: runner = HTMLTestRunner.HTMLTestRunner(f, verbosity=2 , title="单元测试报告" , description="第一次运行结果" ) runner.run(self.discover) if __name__ == "__main__" : mainObj = MainTest() mainObj.main()
TestFixture 对一个测试用例环境的搭建和销毁,就是一个fixture,通过覆盖TestCase的setUp()和tearDown()方法来实现。比如说在这个测试用例中需要访问数据库,那么可以在setUp中通过建立数据库连接来进行初始化,在tearDown()中清除数据库产生的数据,然后关闭连接等。
断言 在一个测试用例中,测试步骤,测试的断言缺一不可。
Unitest提供的断言方法 :
method
检查
assertEqual(a,b)
a==b
assertNotEqual(a,b)
a!=b
assertTrue(x)
bool(x) is True
assertFalse(x)
bool(x) is False
assertIs(a,b)
a is b
assertIsNot(a,b)
a is not b
method
检查
assertIsNone(x)
x is None
assertIsNone(x)
x is not None
assertIn(a,b)
a in b
assertNotIn(a,b)
a not in b
assertIsInstance(a,b)
isinstance(a,b)
assertNotIsInstance(a,b)
not isinstance(a,b)
项目