
Javascript笔记
1.对象
什么是对象?
1.多个数据的封装体
2.用来保存多个数据的容器
3.一个对象代表现实中的一个事物
为什么使用对象?
统一管理多个数据
对象的组成
成员变量(属性)和方法(函数)

es6定义对象
1 | <script> |
判断对象是否为空:
使用Object.keys(对象名).length === 0来判断对象是否为空:
1 | <script> |
2.函数
2.1函数的基本概念
js可以让一个函数成为指定任意对象的方法进行调用
js使用构造函数模拟类
什么是回调函数?
回调函数就是你定义了一个函数,但是你没有调用它,它执行了。
常见的回调函数:dom事件回调函数,ajax请求回调函数,生命周期回调函数,定时器回调函数。
函数中的this指向:
2.1.0函数加括号和不加括号的区别
函数只要是要调用它进行执行的,都必须加括号。此时,函数实际上等于函数的返回值或者执行效果,当然,有些没有返回值,但已经执行了函数体内的行为,就是说,加括号的,就代表将会执行函数体代码。
不加括号的,都是把函数名称作为函数的指针,一个函数的名称就是这个函数的指针,此时不是得到函数的结果,因为不会运行函数体代码。它只是传递了函数体所在的地址位置,在需要的时候好找到函数体去执行。
2.1.1函数声明和函数表达式区别
函数表达式在代码执行到它的时候才会被创建。
函数声明在JavaScript准备运行脚本的时候就被创建,在脚本的任何位置都可见。
1 | console.log(hello) //undefined |
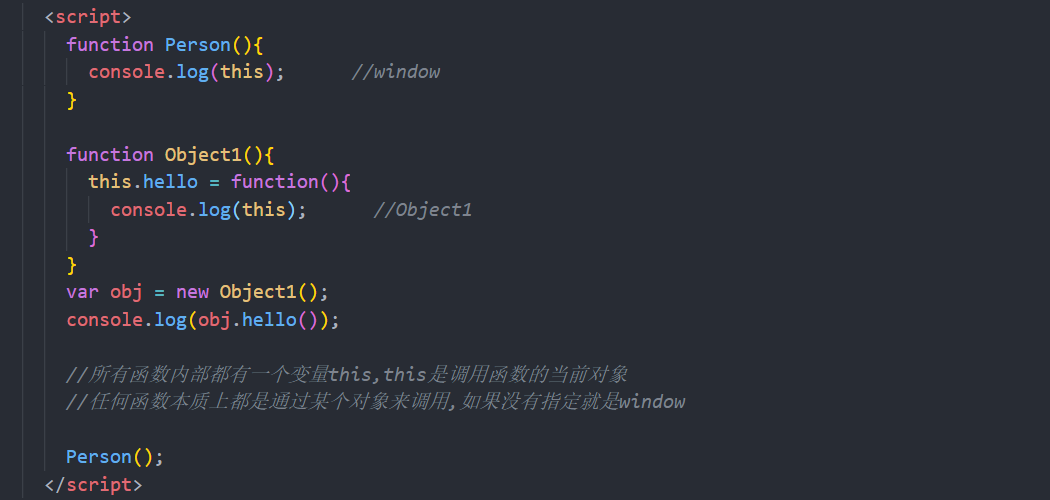
2.2函数的原型对象(prototype)
每个函数都有一个prototype属性,它默认指向一个Object空对象(原型对象)
原型对象有一个constructor,它指向函数对象
1 | console.log(Date.prototype); |
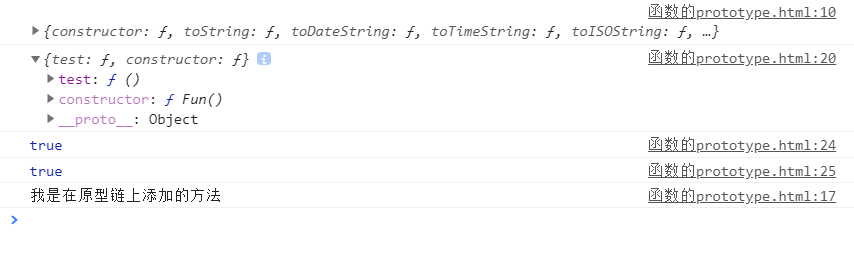
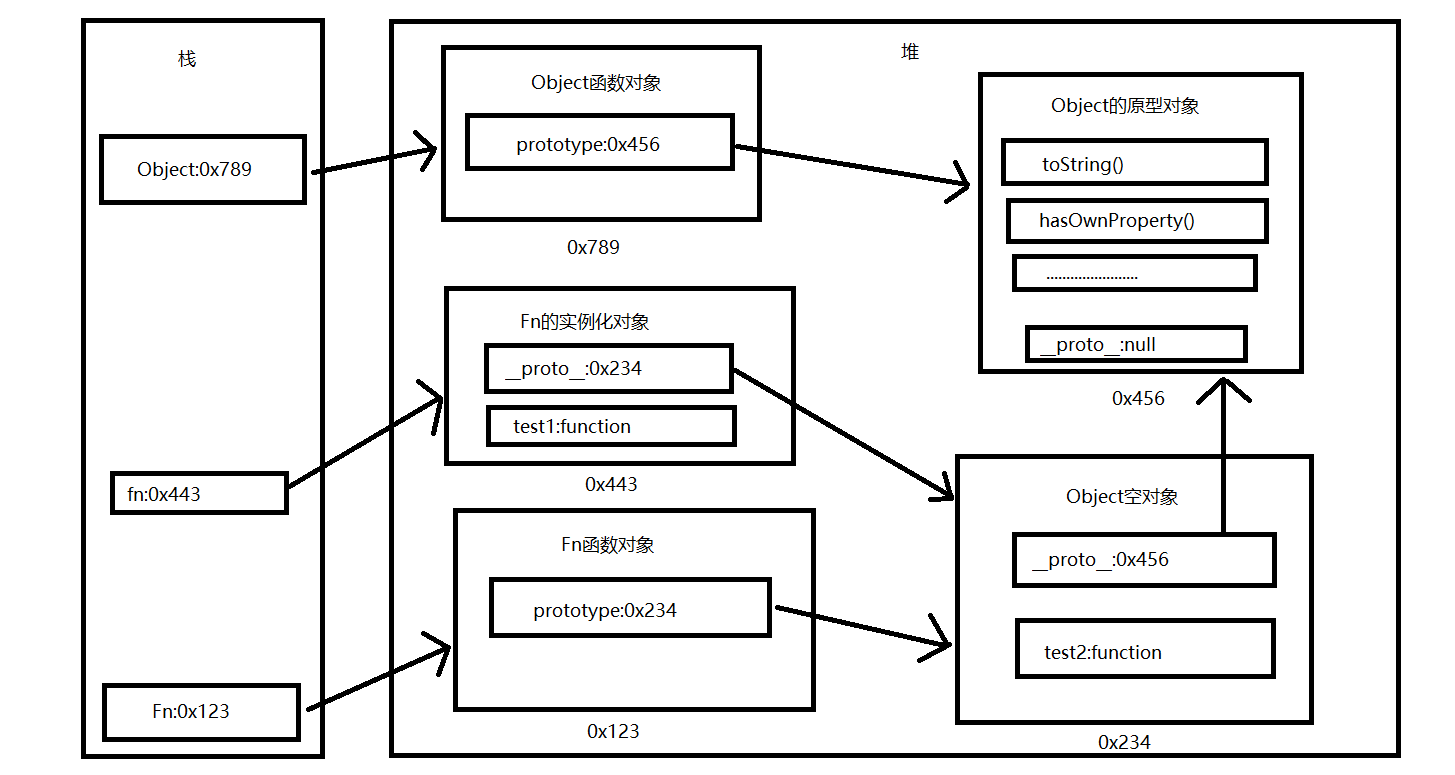
2.3显式原型与隐式原型
1.每个函数function都有一个prototype,即显式原型(属性)
2.每个实例对象都有一个__ proto__,可称为隐式原型(属性)
3.实例对象的隐式原型等于构造函数的显式原型
总结:
- 函数的prototype属性:在定义函数时自动添加,默认值是一个空Object
- 对象的__ proto__属性:创建对象时自动添加的,默认值为构造函数的prototype属性值
- 在创建对象时,内部封装了方法,this.proto = Fn.prototype
- 我们可以直接操作显式原型,但不能直接操作隐式原型(ES6之前)
显式原型跟隐式原型关系图:
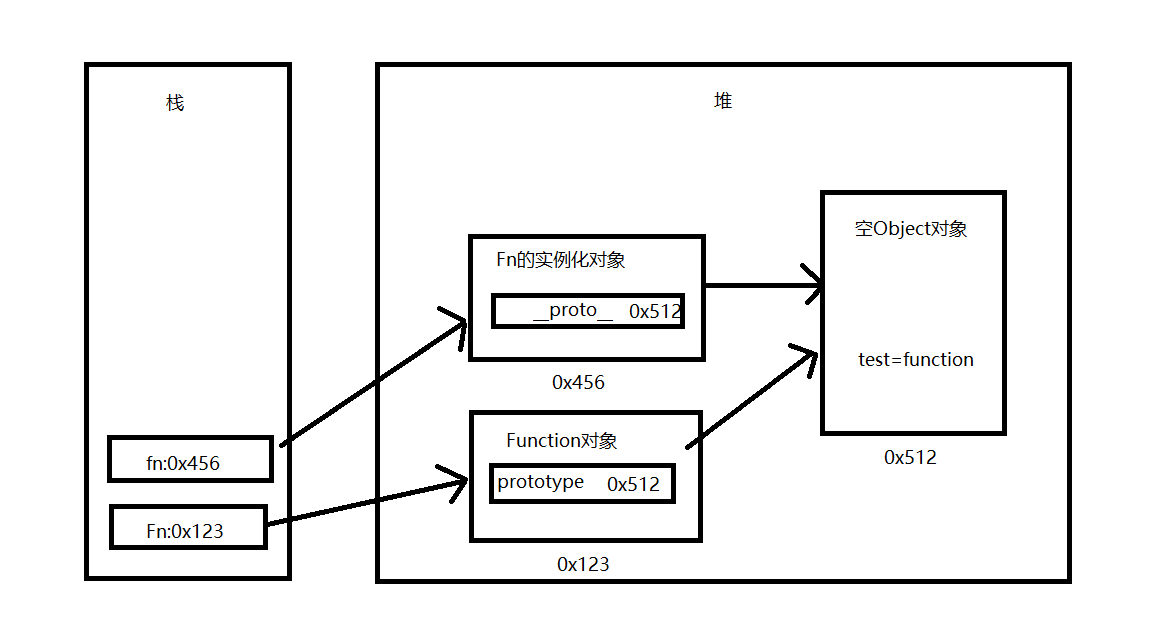
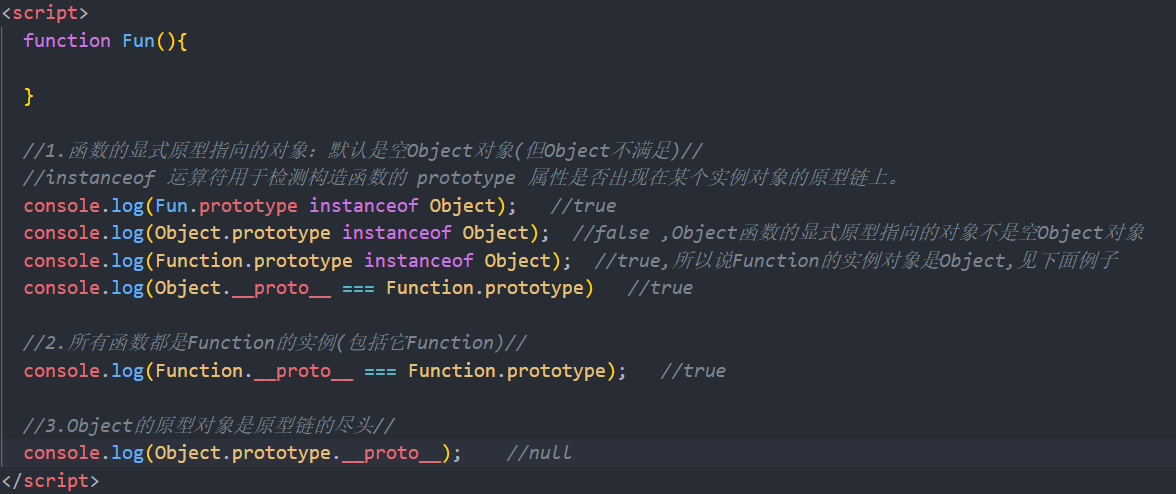
2.4原型链
1 | function Fn(){ |
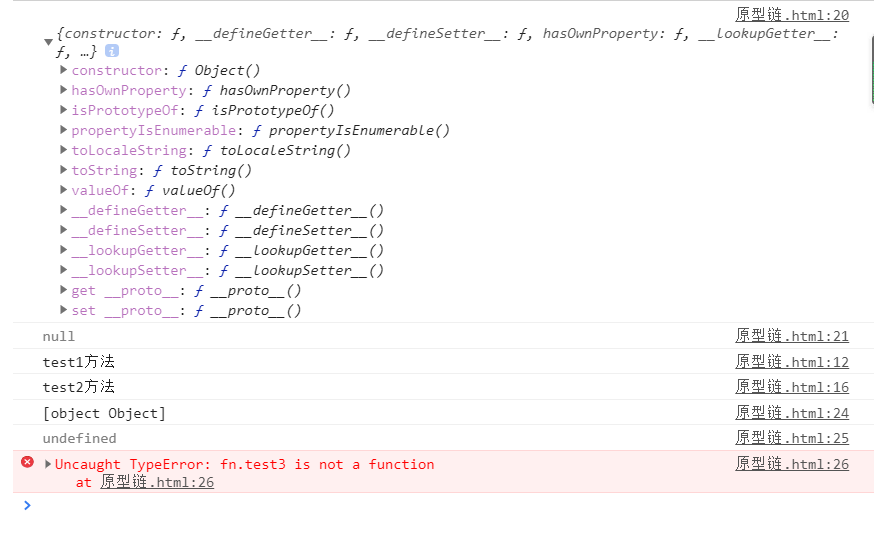
关系图:
1 | console.log(Object.prototype.__proto__); //null |
原型链:访问一个对象的属性时
1.先在自身属性中查找,找到返回
2.如果没有,再沿着__ proto__这条链向上查找,找到返回
3.如果最终没找到,返回undefined
原型链的尽头就是Object的原型对象。
原型链本质上是隐式原型链。
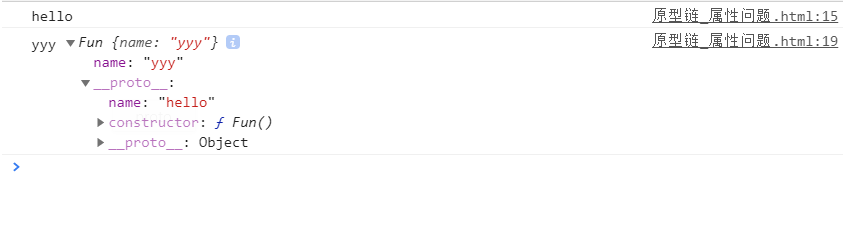
原型链_属性读取问题
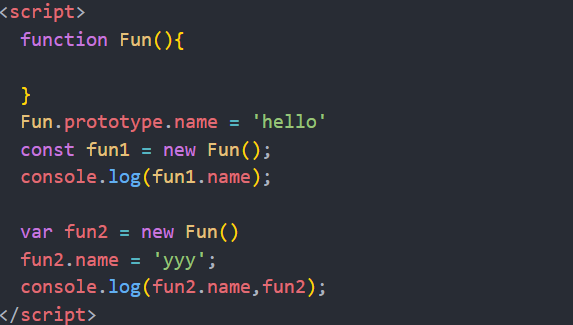
1.读取对象属性值时:会自动在原型链中查找
2.设置对象的属性值时:不会查找原型链,如果当前对象中没有此属性,直接添加此属性并设置其值
3.方法一般定义在原型中,属性一般通过构造函数定义在函数对象本身上
fun2.name = 'yyy'进行属性重写,但是fun1.name的值是不会改变的,因为设置对象的属性值时不查找原型链。
所以一般属性的话,不在原型对象上添加,而在构造函数对象上添加,因为给对象重写属性的时候,是不会查找原型链的,每个对象都应该有自己的特有属性。
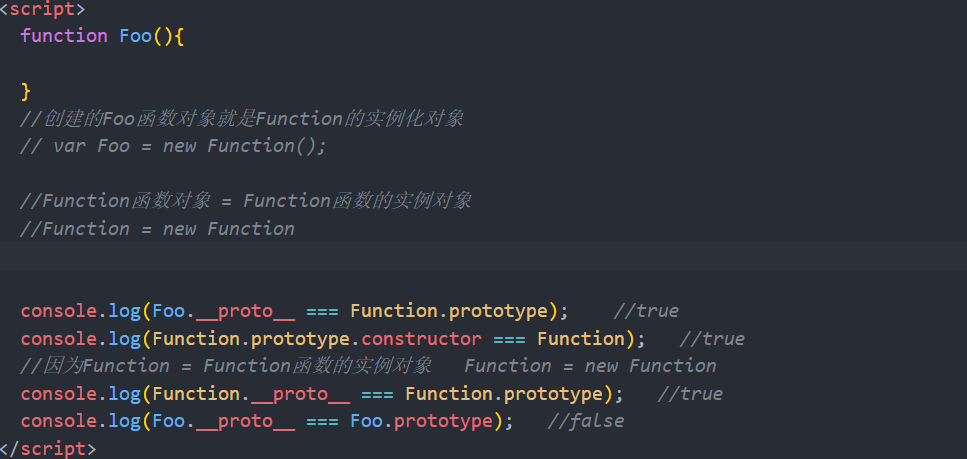
2.5探索instanceof
A instanceof B:B构造函数的显式原型是否在A隐式原型链的其中一个位置。
instanceof方法用来判断左边的对象是不是右边类型的实例。
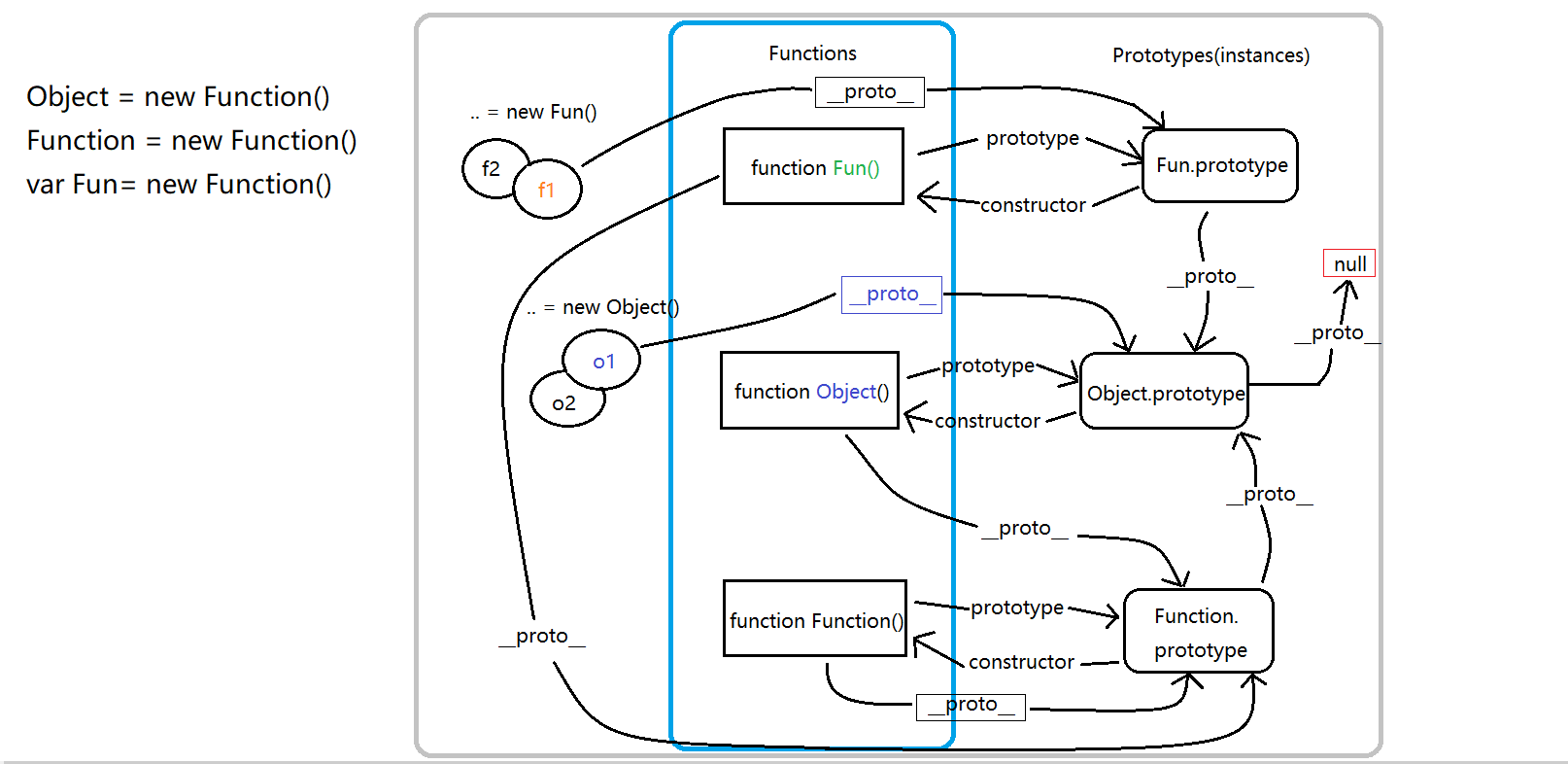
上述图中有点特殊的地方就是:Function的实例对象即是它自己,然后Object是Function的实例对象。
1 | <script> |
2.5.1前端面试题1
1 | <script> |
2.5.2前端面试题2
1 | <script> |
2.6变量提示与函数提升
变量声明提升
通过var定义(声明)的变量,在定义语句之前就可以访问到,添加为Windows的属性。
值:undefined。
相当于声明但是没有定义。
函数声明提升
通过function声明的函数,在之前就可以直接调用,添加为WIndows的属性。
值:函数定义(对象)
1 | <script> |
2.6.1执行上下文
当代码运行时,会产生一个对应的执行环境,在这个环境中,所有变量会被事先提出来(变量提升),有的直接赋值,有的为默认值 undefined,代码从上往下开始执行,就叫做执行上下文。
在 JavaScript 的世界里,运行环境有三种,分别是:
1.全局环境:代码首先进入的环境
2.函数环境:函数被调用时执行的环境
3.eval函数:https://www.cnblogs.com/chaoguo1234/p/5384745.html(不常用)
全局执行上下文
- 在执行全局代码前将Window确定为全局执行上下文
- 对全局数据进行预处理
- var定义的全局变量==>undefined,添加为Window的属性
- function声明的全局函数==>赋值(fun),添加为Window的方法
- this==>赋值(Window)
- 开始执行全局代码
函数执行上下文
- 在调用函数,准备执行函数体之前,创建对应的函数执行上下文对象(虚拟的,存在于栈中)
- 对局部数据进行预处理
- 形参变量==>赋值(实参)==>添加为执行上下文的属性
- arguments==>赋值(实参列表),添加为执行上下文的属性
- var定义的局部变量==>undefined,添加为执行上下文的属性
- function声明的函数==>赋值(fun),添加为执行上下文的方法
- this==>赋值(调用函数的对象)
- 开始执行函数体代码
2.6.2执行上下文栈
- 在全局代码执行之前,JS引擎就会创建一个栈来存储管理所有的执行上下文对象
- 在全局执行上下文(window)确定后,将其添加到栈中(压栈)
- 在函数执行上下文创建后,将其添加到栈中(压栈)
- 在当前函数执行完后,将栈顶的对象移除(出栈)
- 当所有代码执行完后,栈只剩下window
1 | <script> |
函数执行时,开辟空间(压栈),执行结束后,销毁空间(出栈)。上述代码中栈的最底部是window。
面试题1:
1 | <script> |
结果:
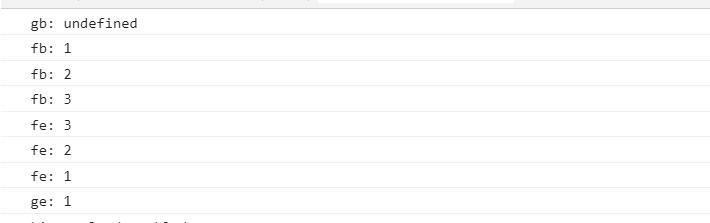
面试题2:
1 | <script> |
2.7作用域和作用域链
1 | <script> |
2.7.1作用域与执行上下文
- 区别1
- 全局作用域之外,每个函数都会创建自己的作用域,作用域在函数定义时就已经确定了。而不是在函数调用时
- 全局执行上下文环境是在全局作用域确定之后,js代码马上执行之前创建
- 函数执行上下文环境是在调用函数时,函数体代码执行之前创建
- 区别2
- 作用域是静态的,只要函数定义好了就一直存在,且不会变化
- 上下文环境是动态的,调用函数时创建,函数调用结束时上下文环境就会被释放
- 联系
- 执行上下文环境(对象)是属于所在的作用域
- 全局上下文环境==>全局作用域
- 函数上下文环境==>对应的函数使用域
2.7.2作用域链
如果出现函数嵌套,最里面的函数如果找不到要输出的变量的值时,它会逐层往外层(往上找),找到即输出。
1 | <script> |
1 | <script> |
2.8闭包
1.如何产生闭包
- 当一个嵌套的内部函数引用了嵌套的外部函数的变量(函数)时,就产生了闭包。
2.闭包的理解
- 理解1:闭包是嵌套的内部函数
- 理解2:包含被引用变量(函数)的对象
3.产生闭包的条件
- 函数嵌套
- 内部函数引用了外部函数的数据(变量/函数)
常见的闭包代码:
1 | <script> |
闭包的作用:
- 使用函数内部的变量在函数执行完后,仍然存活在内存中(延长了局部变量的生命周期)
- 让函数外部可以操作函数内部的数据
闭包的生命周期:
1 | <script> |
闭包的缺点:因为函数调用后不直接销毁,容易造成内存泄露。
- 内存溢出:
- 当程序运行需要的内存超过了剩余的内存时,就会抛出内存溢出的错误。
- 内存泄漏:
- 占用的内存没有及时释放
- 内存泄漏过多就会导致内存溢出
- 常见的内存泄露
- 意外的全局变量
- 没有及时清理计时器或回调函数
- 闭包
闭包的应用:定义js模块
- 具有特定功能的js文件
- 将所有的数据和功能都封装在一个函数内部(私有的)[函数外部操作函数内部的数据]
- 只向外暴露一个包含n个方法的对象或函数
- 模块的使用者,只需要通过模块暴露的对象调用方法来实现对应的功能
3.对象创建模式
3.1工厂模式:
1 | <script> |
3.2构造函数+原型的组合模式
1 | <script> |
、
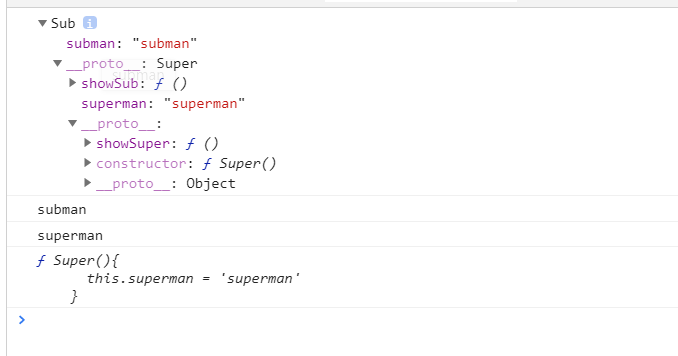
4.原型继承
核心:一般函数对象原型指向一个空Object对象,但是为了实现继承,我们把函数对象原型指向它要继承的函数对象的实例对象,然后到时候找的时候,会根据实例对象的隐式原型链一直往上找。
1 | <script> |
5.线程机制与事件机制
- 一个进程内的数据可以供其中的多个线程直接共享
- 多个进程之间的数据是不能直接共享的
- 线程池:保存多个线程对象的容器,实现线程对象的反复利用
5.0浏览器的内核组成
- 主线程:
- js引擎模块:负责js程序的编译与运行
- html,css文档解析模块:负责页面文本的解析
- DOM/CSS模块:负责dom/css在内存中的相关处理
- 布局和渲染模块:负责页面的布局和效果的绘制(内存中的对象)
5.1单线程与多线程的优缺点
多线程
优点:
- 能够有效提升CPU的利用率
缺点:
创建多线程开销
线程之间切换开销
死锁与状态同步问题
单线程
- 优点:
- 顺序编程简单易懂
- 缺点:
- 效率低
- 优点:
5.2 js是单线程的
- 如何证明js是单线程执行的?
- setTimeout()的回调函数是在主线程执行的
- 定时器回调函数只有运行栈中的代码全部执行完后才有可能执行
- 为什么js要用单线程模式,而不用多线程模式?
- javascript的单线程,与它的用途无关
- 作为浏览器脚本语言,javascript的主要用途是与用户互动,以及操作Dom。
- alert会暂停主线程的执行,同时暂停计时函数,只有结束后,恢复程序执行和计时
- 回调代码不能同时执行,必须要先后执行。这也是一种单线程的体现
1 | <script> |
5.3事件循环模型
- 初始化执行代码(同步代码):包含绑定dom事件监听,设置定时器,发送ajax请求的代码
- 回调执行代码(异步代码):处理回调逻辑
- js引擎执行代码的基本流程:
- 初始化代码==>回调代码
- 回调队列
- 模型的两个重要组成部分
- 事件(定时器?DOM事件/ajax…)管理模块
- 回调队列
- 模型的运转流程
- 执行初始化代码,将事件回调函数交给对应管理模块
- 当事件发生时,管理模块会将回调函数及其数据添加到回调队列中
- 只有当初始化代码执行完后(可能要一定时间),才会遍历读取回调队列中的回调函数执行。
5.4Web Workers多线程
- 什么是Web Workers多线程?
- Web Workers是html5提供的一个JavaScript多线程解决方案
- 我们可以将一些大计算量的代码(比如斐波那契数列代码)交由Web Worker运行而不冻结用户界面
- 但是子线程完全受主线程控制,且不得操作DOM。所以这个新标准并没有改变JavaScript单线程的本质。
斐波那契数列的实现:
1 |
|
以上代码在执行的时候,当给的数值过大,浏览器就会卡住。
使用Web Worker多线程方式:
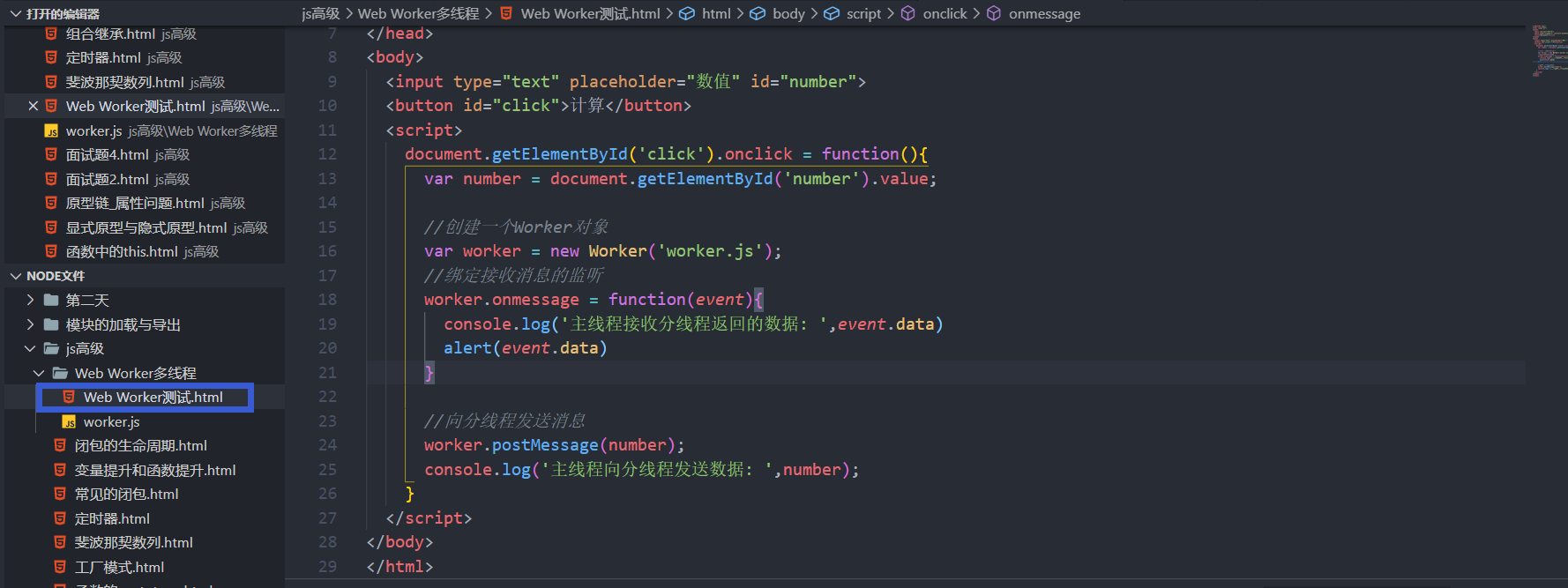
主线程跟分线程的核心通信在于postMessage方法。
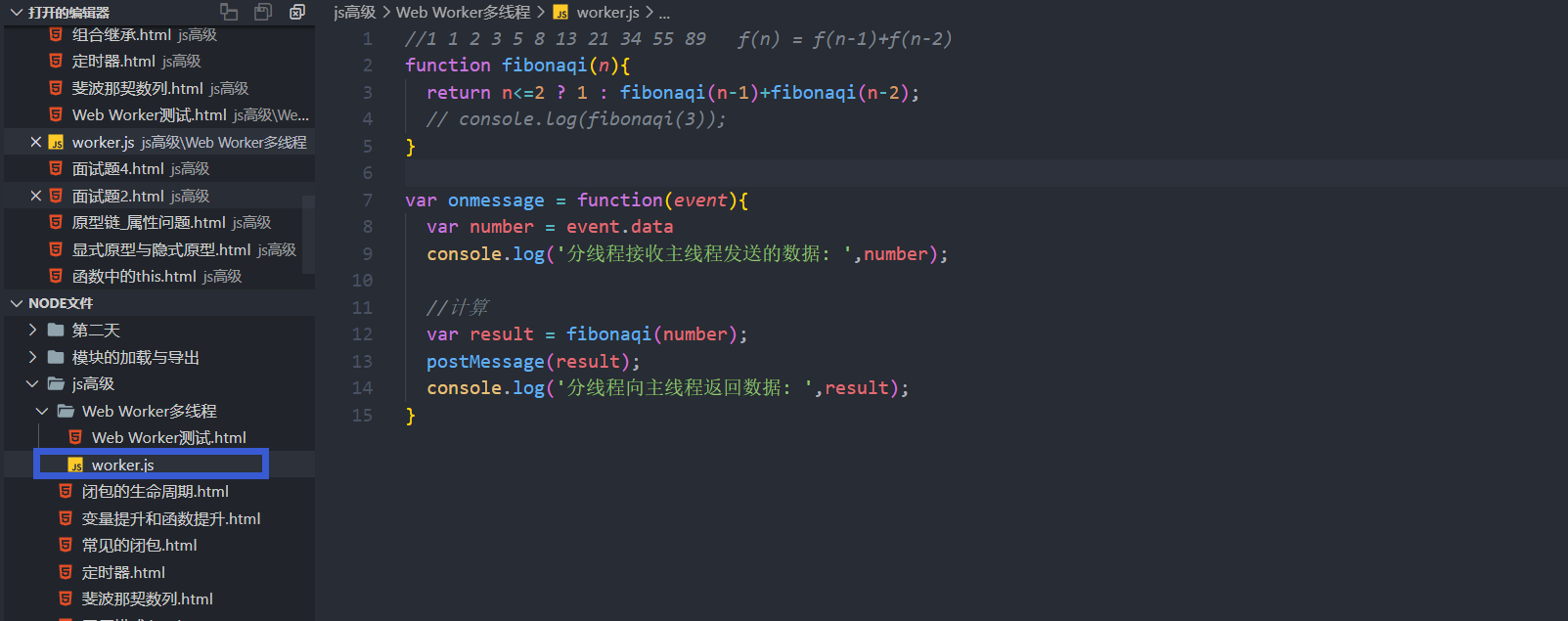
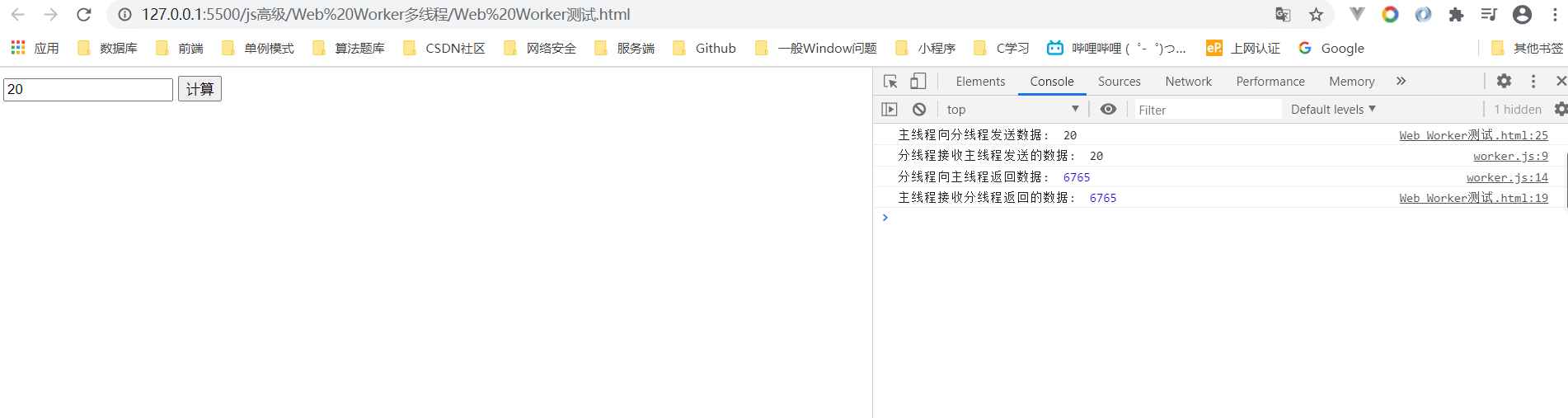
使用了Web Worker,它会把计算过程交给分线程处理,处理完成之后会将结果返回给主线程。如此一来,浏览器就不会卡顿了。
最大的问题是:不是每个浏览器都兼容此特性。
workder内的代码是不能访问DOM的,因为worker的全局对象不是window,而是DedicatedWorkerGlobalScope函数。
6.深拷贝和浅拷贝的区别
6.1什么是堆和栈?
堆和栈其实是两种数据结构。堆栈都是一种数据项按顺序排列的数据结构,只能在一端(栈顶)对数据项进行插入和删除操作。堆和栈是个特殊的存储区,主要功能是暂时存放数据和地址。
- 栈:由操作系统自动分配释放,存放函数的参数值和局部变量的值等。当定义一个变量的时候,计算机会在内存中开辟一块存储空间来存放这个变量的值,这块空间就叫做栈,然而栈中一般存放的是基本数据类型(
undefined,boolean,number,string,null),栈的特点是先进后出(后进先出)。 - 堆:一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收,分配方式类似于链表。在堆中一般存放的是对象和数组类型。
6.1基本数据类型存放在栈中
js的基本数据类型:undefined,boolean,number,string,null
1 | var a = 10; |
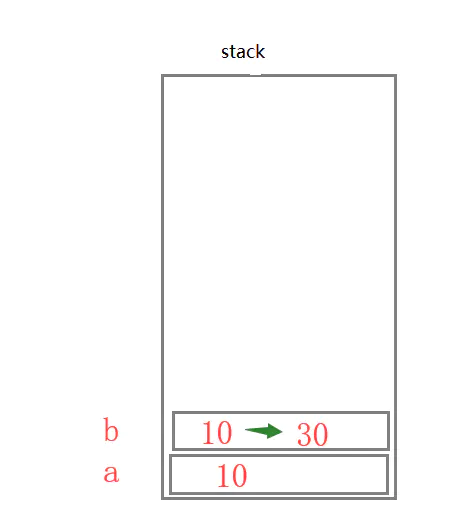
当你声明一个变量,首先看声明的数据是什么类型的?是基本数据类型还是引用数据类型?上面案例为定义的是基本数据类型,基本数据类型则都存放在栈中,计算机会在栈中给你开辟一个内存空间去存储这个变量,当你去改变b的时候,那也只是去改变了b,所以a空间的值是不会受到任何影响,所以第一道题会打印出来10。
1 | var a = 20; |
6.2引用类型存放在堆中
引用类型(对象或数组)是存放在堆内存中的,变量实际上是一个存放栈内存的指针,这个指针指向堆内存中的地址,堆中存放着数据。
1 | var obj = { |
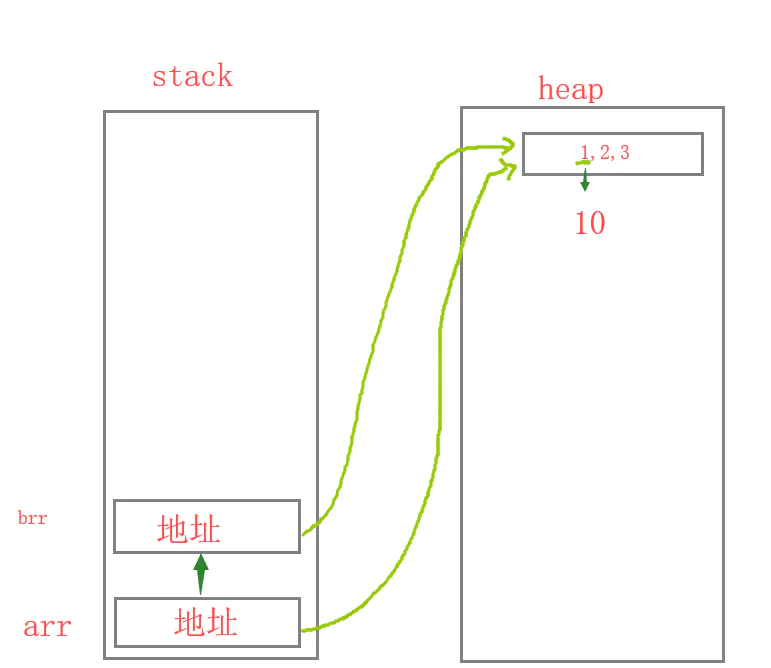
上面案例中声明的变量是数组和对象类型,所以引用类型存放在堆中。如果定义一个arr = [ ],在栈中就会存储一个地址,在堆中就会存储对应该地址的值,这个地址就会指向对应的数据。地址在计算机中叫做指针变量,brr = arr 叫做地址传值,现在brr的地址跟arr一样,它们在堆中指向相同的位置,如果改变arr[0]的话,brr[0]也跟着改变了,如果改变brr[0]的话,arr[0]也改变了,这种地址传值修改数据的时候一改全改。
6.3浅拷贝
1 | var obj1 = { |
obj1:原始数据obj2:赋值操作得到obj3:浅拷贝得到
我们可以看到无论改变obj1还是obj2的属性值,它两都会同时改变,而obj3没有改变,因为obj1和obj2都指向相同的地址,而obj3则指向了新的对象,所以被叫为浅拷贝,但是obj3中有个数组类型的数据,当改变这个数组的数据时,无论是修改赋值得到的对象 obj2 和浅拷贝得到的 obj3 都会改变原始数据。这是因为浅拷贝没有复制对象中的引用类型数据(原数组中包含的子对象)。所以就会出现改变浅拷贝得到的 obj3 中的引用类型时,会使原始数据得到改变。
浅拷贝:将 B 对象拷贝到 A 对象中,但不包括 B 里面的子对象。
深拷贝:将 B 对象拷贝到 A 对象中,包括 B 里面的子对象。
| – | 和原数据是都指向同一对象 | 第一层数据为基本数据类型 | 原数据中包含子对象 |
|---|---|---|---|
| 赋值 | 是 | 改变会使原数据一同改变 | 改变会使原数据一同改变 |
| 浅拷贝 | 否 | 改变不会使原数据一同改变 | 改变会使原数据一同改变 |
| 深拷贝 | 否 | 改变不会使原数据一同改变 | 改变不会使原数据一同改变 |
6.4深拷贝
7.async和await
async是”异步”的简写,而await可以认为”async wait”的简写。async用于申明一个function是异步的,而await用于等待一个异步方法执行完成。
async是让方法变成异步。
await是等待异步方法执行完成。
8.JSON
JavaScript Object Notation(JavaScript对象标记),简称JSON,是一种数据交换格式。
在实际开发中,系统和系统之间,有两种交换数据的格式,一种是JSON,另一种是XML。
XML体积较大,解析麻烦,但是其优点是语法严谨。
Author: 小灰灰
Link: http://xhh460.github.io/2020/06/24/js%E7%AC%94%E8%AE%B0/
Copyright: All articles in this blog are licensed.